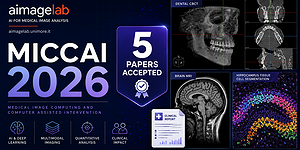
Deep-Learning and HPC to Boost Biomedical Applications for Health (
DeepHealth in short) project has been funded by the EC under the topic ICT-11-2018-2019 "HPC and Big Data enabled Large-scale Test-beds and Applications". DeepHealth is a 3-year project, kicked-off in mid January 2019 and is expected to conclude its work in December 2021. The aim of DeepHealth is to offer a unified framework completely adapted to exploit underlying heterogeneous HPC and Big Data architectures; and assembled with state-of-the-art techniques in Deep Learning and Computer Vision. The project has received funding from the European Union’s Horizon 2020 research and innovation program under grant agreement No 825111. Our research team will be involved in the development of the European Computer Vision Library (
ECVL), the front-end of the DeepHealth toolkit, and will be responsible for the skin lesion segmentation and classification use case.